
PythonのPandasは、機械学習やディープラーニングをする上で欠かせないライブラリの1つです。Pandasを使用することで、データの可視化や加工を行うことができます。
Pandasのことを紹介されている記事はたくさんあるのですが、少し細かすぎるなと思っています。最低限これだけ知っていれば、ある程度のデータ操作はできるという切り口でPandasについてまとめています。
この記事の他に、NumpyやMatplotlibについてもまとめていますので、よろしければご確認下さい。
Pandasとは
Pandasについて、公式では以下のように説明がされています。
pandasは、高速、強力、柔軟、かつ使いやすいオープンソースのデータ分析・操作ツールです、
pandas – Python Data Analysis Library (pydata.org)
プログラミング言語Pythonの上に構築されています。
Pandasは公式で記載されている通り、ほんとに便利で高機能です。ただし、高機能が故にたくさんの機能があるため、本当に使うものに絞ってご紹介します。
Pandasを使うにあたって
pandasには、データを扱うDataFrame型とSeries型の2種類のデータ構造があります。
Series型
Series型は1列もしくは1行のみでデータを持つテーブルになります。
| age | |
| 1 | 45 |
| 2 | 23 |
| 3 | 20 |
| 4 | 39 |
Series型でもインデックスは持つことができ、一番左の列名が空白の部分がインデックスになります。
DataFrame型
DataFrame型は複数列、複数行でデータを持つテーブルになります。Pandasでは基本的にDataFtane型でデータを扱います。
| Name | Age | Weight | height | |
| 1 | Yamada | 23 | 172 | 58 |
| 2 | Tanaka | 38 | 151 | 42 |
| 3 | Sasaki | 54 | 166 | 65 |
| 4 | Suzuki | 22 | 178 | 72 |
迷ったらDataFrame型に変換でよし
基本的にDataFrame型のみ使用する形で良いです。Series型の操作まで覚えるのは大変なので、Series型のデータは迷わずDataFrame型へ変換してしまえばOKです。
変換方法は、Series型のデータを.to_frame() で一発でDataFrame型へ変換できます。
Pandasを使う準備
Pandasのインストール
以下のコマンドより、Pandasをインストールします。
pip install pandasPandasのインポート
以下のコマンドより、Pandasをインポートします。
import pandas as pdPandasのデータ読込み
Pandasを使うには、まずはデータを読み込む必要があります。
pd.read_csv()
df.read_csv(’ファイルパス’)でcsv形式のファイルを読み込むことができます。
df = pd.read_csv('data/test.csv')pd.read_excel()
excelを読み込む場合はxlrdが必要となりますので、インストールしてください。
pip install xlrdその後はcsvと同じ形で読み込むことができます。
df = pd.read_excel('test.xlsx')上記は初めのシートが読み込まれますが、読み込むシートを指定することも可能です。
df = pd.read_excel('test.xlsx, sheet_name=Sheet2')Pandasのデータ出力
Pandasでデータの読込みをするのと同じ要領です。
df.to_csv()
df.to_csv(’ファイルパス’) で指定のフォルダへcsv形式で出力することができます。
df.to_csv('data/test.csv')df.to_excel()
df.to_excel(’ファイルパス’) で指定のフォルダへexcel形式で出力することができます。
df.to_excel('data/test.xlsx')index(行名), columns(列名)を除いて出力することもできます。
df.to_excel('data/test.xlsx',index=False,header=False)Pndansのデータ確認
データ構造について、実際のデータを用いて確認していきます。
seabornライブラリからサンプルのデータを取得することができます。今回はディナーとランチの総支払額とチップの額を支払った人の性別や喫煙の有無などが分類された個人のデータを使っていきます。
import seaborn as sns
df = sns.load_dataset('tips')df.head()
データの中身を確認したい時に使用します。
df.head()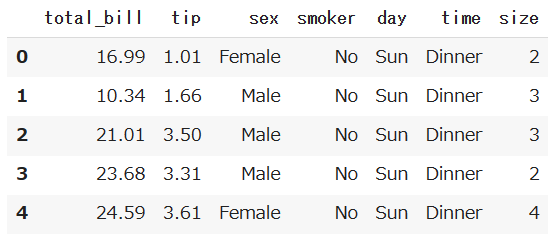
デフォルトで先頭から5行を出力します。
出力させたい行数を指定するとその行数分だけ出力することが可能です。
df.head(10)df.tail()
データの中身を一番下の行から確認したい時に使います。
df.tail()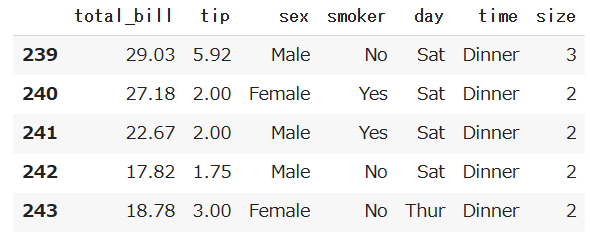
df.shape
データの行数と列数を確認したい時に使います。
df.shape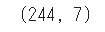
Pandasのデータ抽出
特定の列や行のデータを抽出していきましょう。
df.loc[]
特定の列または行の名前を指定して、好きなようにデータを抽出することができます。
df.loc[:5,:'tip']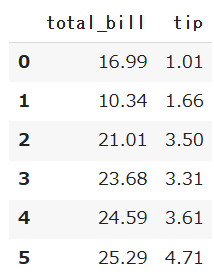
df.iloc[]
特定の列または行の数を指定して、好きなようにデータを抽出することができます。
df.iloc[:6,:2]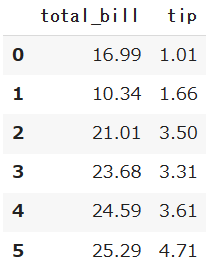
Pandasの列・行削除
続いて、データの列と行を削除する方法です。
df.drop()
行削除
df.drop()の引数にaxis=0を指定すると、指定する行を削除することができます。
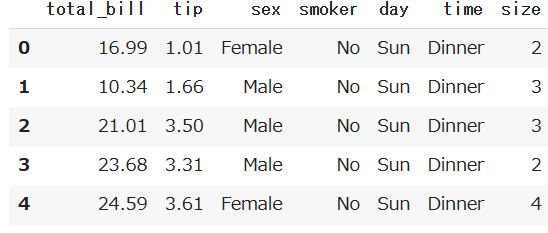
このデータの1行目(indexが0の行)を削除します。
df.drop(0, axis=0)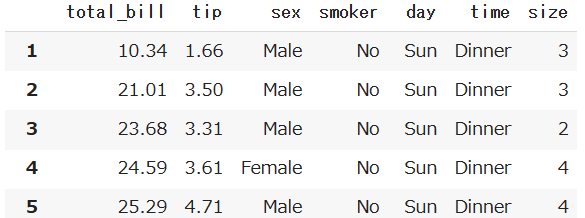
結果を見ると削除できていますね。
列削除
df.drop()の引数にaxis=1を指定すると、指定する行を削除することができます。
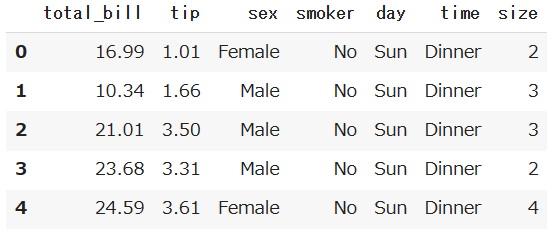
このデータの「tip」列を削除します。
df.drop("tip", axis=1)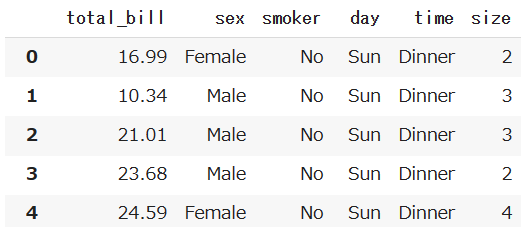
「tip」列が削除されてますね。
Pandasのデータ結合
複数のデータを結合する時にpd.concat()またはpd.merge()を使います。
pd.concat()とpd.merge()の違いについて少し分かりづらいかもしれませんが、concatは単純に横、縦方向に結合をすることができ、mergeは横方向にのみ、特定の列をキーとして指定して結合することができます。
concatとmergeでそれぞれデータを用意して、結合の仕方について確認していきましょう。
pd.concat()
concatで結合するためのデータを準備します。
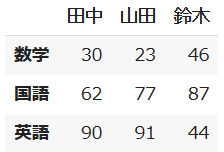
df1 = pd.DataFrame({"田中": [30, 62, 90],
"山田" : [23, 77, 91],
"鈴木" : [46, 87, 44]},
index = ["数学", "国語", "英語"])
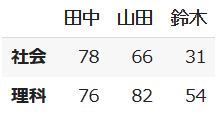
df2 = pd.DataFrame({"田中": [78, 76],
"山田" : [66, 82],
"鈴木" : [31, 54]},
index = ["社会", "理科"])df1のデータは次の通りです。
df2のデータは次の通りです。
次にdf1とdf2を縦方向に結合します。
concatで縦方向に結合する場合は引数にaxis=0 を指定し、横方向に結合したい場合はaxis=1を指定します。今回は縦方向に結合したいのでaxis=0を指定します。
df3 = pd.concat([df1, df2], axis=0)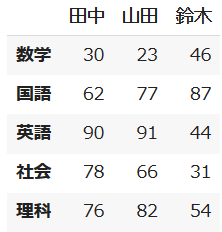
pd.merge()
mergeで結合するためのデータを準備します。
df1 = pd.DataFrame({'key': ['A', 'B', 'C', 'D'],
'value': [1, 2, 3, 4]})
df2 = pd.DataFrame({'key': ['B', 'D', 'E', 'F'],
'value': [5, 6, 7, 8]})df1のデータは次の通りです。

df2のデータは次の通りです。
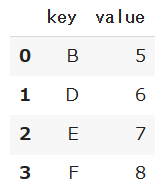
df1とdf2で共通するkeyの値のデータのみを結合したいとする場合、mergeで結合キーに「key」を指定して結合をします。
df3 = pd.merge(df1, df2, on='key')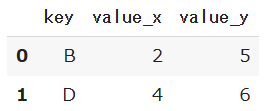
Pandasのデータ加工・集計
続いてデータの加工・集計について確認していきましょう。
df.describe()
これはかなり便利で、各列ごとに平均や標準偏差、最大値、最小値、最頻値などの要約統計量を出すことができます。
df.describe()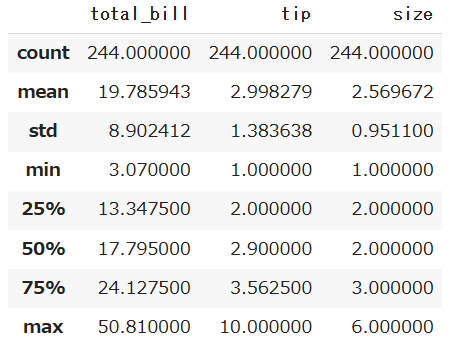
df.corr()
各カラムごとに相関係数を算出して、相関関係を確認することが可能です。
df.corr()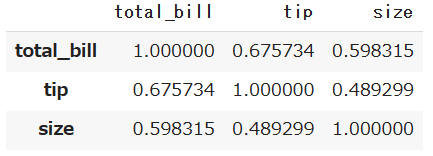
df.value_counts()
出現の回数をカウントして集計することができます。例えば、喫煙者の数を集計します。
df["smoker"].value_counts()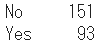
df.groupby()
ある項目をキーにして集計することができます。例えば、性別ごとにチップの金額の平均を集計します。
df.groupby('sex')['tip'].mean()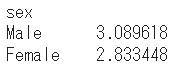
df.sort_values()
ある項目をキーにして順番を並び替えることができます。例えば、チップの金額を昇順に並び替えます。
df.sort_values('tip')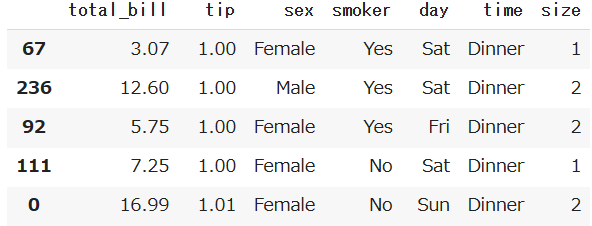
チップの金額が昇順になりましたね。降順にしたい場合は、次の通りに引数を指定します。
df.sort_values('tip',ascending=False)df.isnull()
データの中身に欠損値(何もないデータ)がないか確認することができます。
df.isnull().sum()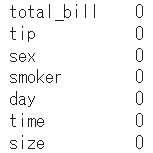
今回使用しているサンプルデータの中身に欠損値はないことが分かります。
df.dropna()
欠損値が入っている行を一括で削除することができます。
df.dropna()今回使っているサンプルデータには欠損値がないため、削除される行はありません。
df.fillna()
欠損値のある部分に対して、指定した数値に一括で置き換えることができます。
df['tip'].fillna(0)今回使っているサンプルデータには欠損値はありませんが、欠損値がある場合は0埋めしてくれます。
pythonのおすすめ勉強法
そもそもpythonの知識を1から学びたいという人にマジでおすすめなpythonの勉強方法をご紹介します。
結論から言うと、Udemyを活用することです。私はPythonを以下の講座のみで学びましが、本当に分かりやすく最強だと思っています。実際に講座を見ながら自分も手を動かして学習できるので、しっかりと身に付きます。
まとめ
pandasについて一通りの処理をまとめましたが、これだけ知っていれば、pythonでpandasを使ってそれなりにデータを確認することや、分析することができると思います。
pandasの操作が分からなくなってしまった場合は、ここのページを確認して辞書変わりに使っていただけると幸いです。
コメント